14 Homework 4: Hypothesis testing
Directions:
Install the
lubridateandggmappackages in your console:Start a new RMarkdown document.
Load the following packages at the top of your Rmd:
dplyr,ggplot2,fivethirtyeight,infer,broom,lubridate,ggmap
Goals:
In this homework you will
- solidify your understanding of hypothesis tests;
- take a bootstrapping approach to hypothesis testing; and
- explore some common snags in hypothesis testing.
14.1 Bootstrap hypothesis testing + multicollinearity
The bf data contains body measurements on 250 adult males. The original data are from K. Penrose, A. Nelson, and A. Fisher (1985), ”Generalized Body Composition Prediction Equation for Men Using Simple Measurement Techniques” (abstract), Medicine and Science in Sports and Exercise, 17(2), 189.
- BodyFat vs Hip & Weight
Construct the sample model of body fat percentage (
BodyFat) byHipcircumference (cm) andWeight(lb). Review theWeightcoefficient before moving on.Report & interpret the test statistic for the
Weightcoefficient.Report & interpret the p-value corresponding to the hypothesis that
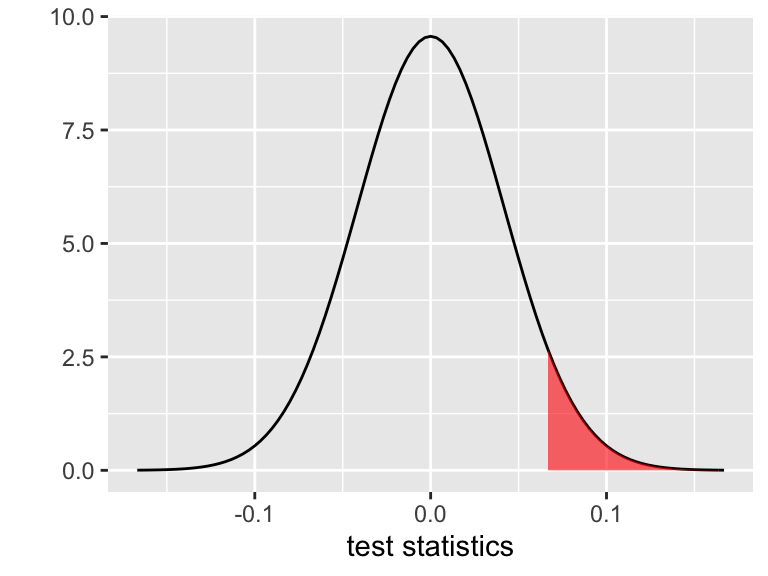
Weightis positively associated withBodyFat.Recall that this p-value is calculated under the assumption that the CLT holds: IF \(H_0: \beta = 0\) holds, then \(\hat{\beta} \sim N(0, 0.0417^2)\). Thus the p-value is represented by the area of the shaded region below. Calculate this Normal probability using
pnorm(). Bonus: usept()for the \(t\) probability that’s actually reported in the summary table.
- Bootstrap hypothesis tests
Our hypothesis test conclusions depend in part on the p-value which depends upon the CLT which depends upon the validity of our model assumptions. Instead of relying on the parametric CLT assumption, we can calculate a bootstrap p-value.- Obtain 1000 bootstrap estimates of the
Weightparameter (for the same model as above with bothWeightandHipas explanatory variables).
- Create a new variable of
null_slopeswhich shifts your bootstrapWeightcoefficients so that they’re centered at 0, the null hypothesis value of theWeightcoefficient. Construct and describe a density plot of the 1000 bootstrapnull_slopes.
- Using only the 1000
null_slopeswith no CLT assumptions, approximate a p-value for the hypothesis test above. (This should be within \(\pm 0.03\) of what you observed for the classical approach!)
- Obtain 1000 bootstrap estimates of the
- A new model
- Noting that the p-value of the
Weightcoefficient is rather high, your friend concludes that weight isn’t associated with body fat percentage. Construct a model that refutes your friend’s mistake, report the model summary table, and provide specific evidence from this table that contradicts your friend’s claim.
- Explain why this happened, i.e. why the original model and your new model provide two different insights into the relationship between body fat percentage and weight.
- Noting that the p-value of the
TAKE HOME WARNING
The coefficient-related hypothesis tests reported in the model summary table must be interpreted in light of the other variables in the model. They indicate the significance of a term on top of / when controlling for other variables in the model, not simply the significance of a term on its own. This is especially important to keep in mind when working with multicollinear predictors. Thus it’s a good idea to start simple - examine models with fewer terms before jumping right into more complicated models!
14.2 Simpson’s Paradox
The data set
contains data on price, carat (size), color, and clarity of 308 diamonds. We want to explore the association between clarity & price. Clarity is classified as follows (in order from best to worst):
| Clarity | Description |
|---|---|
| IF | internally flawless (no internal imperfections) |
| VVS1 | very very slightly imperfect |
| VVS2 | |
| VS1 | very slightly imperfect |
| VS2 |
Before answering the questions below, think about what relationships you’d expect to see among these variables!
pricevs.clarity. Consider the relationship betweenprice&clarity.Construct & describe a plot of the relationship between price and clarity.
Construct a sample estimate of the model of
pricebyclarity.Which clarity has the highest predicted value (and what is this value)? Which clarity has the lowest predicted value (and what is this value)? Why are these results surprising? HINT: Don’t forget about the reference level.
Examine the p-values for each coefficient in the model. What do you conclude?
- Confounding variable. The surprising results above can be explained by a confounding variable:
carat.Construct & describe a visualization of the relationship between
price,clarity, andcarat.
Fit the model of
price ~ clarity + carat.
If you want the extra practice (if not, move on): Interpret every coefficient, predict the price of a 0.5 carat VVS2 diamond, and write out a model of
pricebycaratfor the VVS2 group.When controlling for carat, which clarity has the highest expected price? Which has the lowest expected price?
The models with & without
caratlead to different conclusions about the relationship betweenpriceandclarity. This is called a Simpson’s Paradox. Explain why this happened. Construct a graphic to back you up.
14.3 Multiple testing
In a paper published in the Proceedings of the Royal Society B - Biological Sciences (a reputable journal), Matthews et. al. asked mothers about their consumption of 132 different foods. For each food, they tested for an association with a higher incidence of male or female babies. Letting \(p\) be the proportion of babies that are male:
\[ \begin{split} H_0: & p = 0.5 \\ H_a: & p \ne 0.5 \\ \end{split} \]
NOTE: This test is concerned with a single population proportion (that of male babies). The foundations of this test are the same as for those we’ve discussed in class!
Suppose that NONE of the 132 foods are truly linked to rates of male and female babies (i.e. \(H_0\) is true in all 132 cases). Below you’ll simulate what might happen when we test each of these 132 hypotheses, each using data from a different random sample of 50 mothers.
To begin, import the list of 132 types of food:
foods <- read.csv("https://www.macalester.edu/~ajohns24/Data/BabyBoyFood.csv")
head(foods)
## Type
## 1 Beef, ground, regular, pan-cooked
## 2 Shredded wheat cereal
## 3 BF, cereal, rice w/apples, dry, prep w/ water
## 4 BF, sweet potatoes
## 5 Pear, raw (w/ peel)
## 6 Celery, raw- Diet and birth sex. Let’s run an experiment. For each of the 132 foods, we’ll randomly assign 50 expectant mothers to a diet heavy in that food. We’ll then record the number of male/female babies born in each food treatment group.
For each of the 132 food groups, randomly generate the sex of the 50 babies born to mothers in that group:
Notice that
birthscontains 132 rows. Each row indicates which food you fed to the 50 expectant mothers and the number of male/female babies born to these mothers. Which foods have the greatest discrepancy between male/female babies?It’s reasonable to assume that, in the broader population from which we generated these data, there’s no association between birth sex and diet for any of these food groups. Yet for each food, we’ll use our sample data to test whether the birth rate of males significantly differs from 0.5. In doing so we might make a Type I error. What does this mean in our setting?
- Conclude that a food is linked to birth sex when it’s not.
- Conclude that a food is not linked to birth sex when it is.
- Conclude that a food is linked to birth sex when it’s not.
Use the following syntax to test each food group for a significant association with birth sex and add the corresponding p-values to your data set:
Check out your
birthsdata again. What proportion of the 132 tests produced Type I errors, i.e. hadp.value< 0.05 despite the fact that \(H_0\) is true? To what foods do these belong? Can you imagine the newspaper headlines that would trumpet these results?
- Breakfast cereal and birth sex. In the original Matthews’ study, the researchers found and trumpeted a correlation between male babies & mothers that eat breakfast cereal. The “findings” were picked up in popular media (just 1 example). The multiple testing performed in the study & replicated in our simulation is a real concern. In many applications, we might run thousands of hypothesis tests (eg: gene sequencing). Let’s explore the math behind this phenomenon. Assume we conduct each hypothesis test at the \(\alpha=0.05\) level.
If we conduct any single test, what’s the probability of making a Type I error when \(H_0\) is true? (Think back to the notes!)
What if we conduct two tests? Assuming \(H_0\) is true for both, what’s the probability that at least 1 results in a Type I error?
What if we conduct 100 tests?
In general, as the number of tests increase, the chance of observing at least one Type I error increases. One solution is to inflate the observed p-value from each test. For example, the (very simple) Bonferroni method penalizes for testing “too many” hypotheses by artificially inflating the p-value: \[\text{ Bonferroni-adjusted p-value } = \text{ observed p-value } * \text{ total # of tests} \] Calculate the Bonferroni-adjusted p-values for our 132 tests. Of your 132 tests, what percent are still significant? That is, what is the overall Type I error rate?
This is better. But can you think of any trade-offs of the Bonferroni correction?
TAKE HOME WARNING
Don’t fish for significance! If you test enough hypotheses, something will surely pop out as “significant” just by random chance. That is, the more hypotheses you test, the more likely you are to make a Type I error. Interpret others’ work with this in mind - were they fishing for significance? Is it possible that they’re reporting a Type I error? Do you think that you could reproduce their results in a new experiment?
14.4 Statistical vs practical significance
WARNING: Expect RStudio to run a bit slowly in this section. It’s the biggest data set we’ve worked with. If you choose, you can research the cache=TRUE argument for code chunks. If you choose to do so, you need to take care to “uncache” and then “recache” your cached code any time you make changes to that chunk.
You’ve likely seen the “NiceRide” bike stations around the UM campus! They’re the bright green bikes that members and casual riders can rent for short rides. NiceRide shared data here on every single rental in 2016. The Rides data below is a subset of just 40,000 of the >1,000,000 rides.
Rides <- read.csv("https://www.macalester.edu/~ajohns24/Data/NiceRide2016sub.csv")
dim(Rides)
## [1] 40000 8
head(Rides, 3)
## Start.date Start.station Start.station.number
## 1
## 2
## 3 8/21/2016 11:49 15th Ave SE & Como Ave SE 30110
## End.date End.station End.station.number
## 1
## 2
## 3 8/21/2016 11:55 4th Street & 13th Ave SE 30009
## Total.duration..seconds. Account.type
## 1 0
## 2 0
## 3 343 MemberA quick codebook:
Start.date= time/date at which the bike rental began
Start.station= where the bike was picked up
End.date= time/date at which the bike rental ended
End.station= where the bike was dropped off
Total.duration..seconds.= duration of the rental/ride in seconds
Account.type= whether the rider is a NiceRide member or just a casual rider
Let’s clean up this data. Try to do the following in 1 continuous series of pipes
%>%:Rename “
Total.duration..seconds.” as “duration” (or just add a new variable calledduration).
Keep only the
Start.date,Start.station,End.station,duration, andAccount.typevariables. HINT: Investigate theselect()function OR use indexing.
Keep only the rides that lasted > 0 seconds.
Currently, the
Start.dateis a factor variable:Create 2 variables from this infomation, a variable
hoursthat pulls the hour and a factor variablemonthsthat pulls the month. The following will come in handy:
- Duration vs Membership Status
- Construct a visualization of the relationship between a ride’s log(duration) and the membership status of the rider. (Why log? Try using
durationfirst.)
- Construct a model of
log(duration)by membership status. Summarize the estimated difference in the typical duration of rides for casual riders vs members. Be sure to interpret on the non-log scale. Contextually, what do you think explains this difference?
- Do these data provide statistically significant evidence that casual riders tend to take longer rides?
- Construct a visualization of the relationship between a ride’s log(duration) and the membership status of the rider. (Why log? Try using
- Duration vs Month
- Construct a visualization of the relationship between a ride’s
log(duration)and the month in which the ride took place. NOTE: be sure thatmonthsis a factor/categorical variable!
- Construct a model of
log(duration)by month. Summarize the estimated difference in the typical duration of rides in April and May. On the non-log scale, you should find a difference of about 1 minute. Personally, this isn’t enough for me to think “Wow, people take longer rides in April!” That is, the difference is not practically significant.
- Do these data provide statistically significant evidence that casual riders tend to take longer rides? HINT: Check out the p-value.
- Parts b & c illustrate the difference between statistical significance and practical significance:
- Results are only practically significant if the observed effect size (observed difference between means, the magnitude of a regression coefficient, etc) is large enough to have practical meaning.
- Results are statistically significant if the p-value is small. However, a small p-value merely reflects the presence of an effect, not necessarily a meaningful magnitude of that effect.
- Results are only practically significant if the observed effect size (observed difference between means, the magnitude of a regression coefficient, etc) is large enough to have practical meaning.
- Construct a visualization of the relationship between a ride’s
Play Around!
There are a lot of other features of the NiceRide data!
a. Merge theRideswith the locations of theStations:Stations <- read.csv("https://www.macalester.edu/~ajohns24/Data/NiceRideStations.csv") #join the Stations and Rides MergedRides <- Rides %>% left_join(Stations, by=c(Start.station = "Station")) %>% rename(start_lat=Latitude, start_long=Longitude) %>% left_join(Stations, by=c(End.station = "Station")) %>% rename(end_lat=Latitude, end_long=Longitude)
b. Plot a map of the NiceRides around Minneapolis:
```r
MN<-get_stamenmap(c(-93.375,44.86,-93.05,45.04),zoom=14,maptype="terrain")
ggmap(MN) +
geom_segment(data=MergedRides, aes(x=start_long, y=start_lat,
xend=end_long, yend=end_lat), alpha=0.07)
```
c. Do the route distributions/choice differ by membership status? (Construct a visualization.)
d. How if at all does duration change by time of day? By time of day and membership status?
e. What other questions might we ask? Play around and see if you have any insight to add about riding patterns.
14.5 HW4 solutions
Don’t peak until and unless you really, really need to!
- BodyFat vs Hip & Weight
bf <- read.csv("https://www.macalester.edu/~ajohns24/data/bodyfatsub.csv")
bfmod <- lm(BodyFat ~ Hip + Weight, bf)
summary(bfmod)
##
## Call:
## lm(formula = BodyFat ~ Hip + Weight, data = bf)
##
## Residuals:
## Min 1Q Median 3Q Max
## -18.1981 -4.1935 -0.1629 4.5087 18.4368
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -48.52400 10.85559 -4.470 1.19e-05 ***
## Hip 0.56325 0.17501 3.218 0.00146 **
## Weight 0.06417 0.04171 1.538 0.12525
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.418 on 247 degrees of freedom
## Multiple R-squared: 0.406, Adjusted R-squared: 0.4012
## F-statistic: 84.4 on 2 and 247 DF, p-value: < 2.2e-16Weight: When holdingHipconstant, there’s a 0.06 percentage point increase in body fat percent for every extra 1 lb of weight.The estimated
Weightcoefficient is 1.54 standard errors above 0.p = 0.1252 / 2 = 0.0626
If in fact there’s no relationship betweenWeightandBodyFatwhen controlling forHip, there’s a 6% chance we would’ve obtained a sample in which the association between these variables is as strong / stronger than what we observed.
pnorm(0.0642, mean = 0, sd = 0.0417, lower = FALSE)
## [1] 0.0618328
pnorm(1.54, mean = 0, sd = 1, lower = FALSE)
## [1] 0.06178018
pt(1.54, df = 247, lower = FALSE)
## [1] 0.06242023
- Bootstrap hypothesis tests
set.seed(2018)
#a
bf_boot <- rep_sample_n(bf, size = 250, reps = 1000, replace = TRUE) %>%
do(lm(BodyFat ~ Weight + Hip, data = . ) %>% tidy()) %>%
filter(term == "Weight")
#b
# mean of all estimates
(mean_weight_coeff<-mean(bf_boot$estimate))
## [1] 0.06510389
# shift estimates to center around 0
bf_boot <- bf_boot %>%
mutate(null_slopes = estimate - mean_weight_coeff)
# mean of null slopes is now 0
mean(bf_boot$null_slopes)
## [1] 9.45614e-19
ggplot(bf_boot, aes(x = null_slopes)) +
geom_density()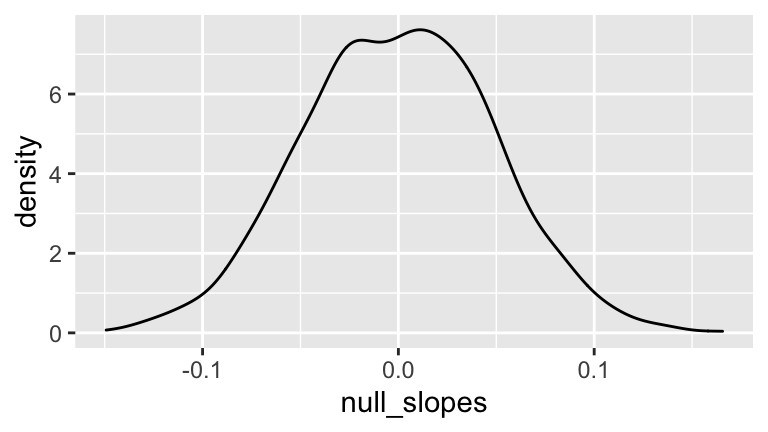
#c
# approximate p-value by proportion of boot slopes
# that exceed our sample slope
mean(bf_boot$null_slopes >= 0.0642)
## [1] 0.092
- A new model
- .
bfmod2 <- lm(BodyFat ~ Weight, bf)
summary(bfmod2)
##
## Call:
## lm(formula = BodyFat ~ Weight, data = bf)
##
## Residuals:
## Min 1Q Median 3Q Max
## -18.412 -4.744 -0.023 4.950 20.720
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -14.69314 2.76045 -5.323 2.29e-07 ***
## Weight 0.18938 0.01533 12.357 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.538 on 248 degrees of freedom
## Multiple R-squared: 0.3811, Adjusted R-squared: 0.3786
## F-statistic: 152.7 on 1 and 248 DF, p-value: < 2.2e-16- Weight and hip circumference are multicollinear. On top of what’s already explained by hip about body fat, weight doesn’t add a significant amount of information:
pricevs.clarity.
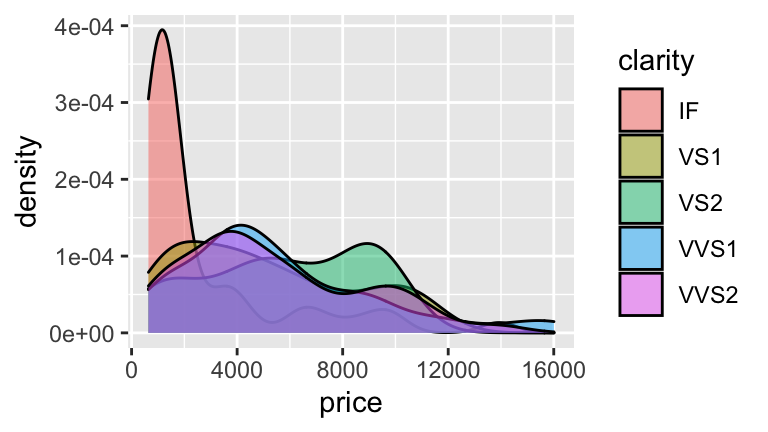
#b
mod1 <- lm(price ~ clarity, diam)
summary(mod1)
##
## Call:
## lm(formula = price ~ clarity, data = diam)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5220.2 -1940.0 -990.9 2063.5 11218.2
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2694.8 494.2 5.453 1.03e-07 ***
## clarityVS1 2362.3 613.9 3.848 0.000145 ***
## clarityVS2 3163.4 668.5 4.732 3.42e-06 ***
## clarityVVS1 2872.9 671.4 4.279 2.52e-05 ***
## clarityVVS2 2661.8 618.0 4.307 2.24e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3278 on 303 degrees of freedom
## Multiple R-squared: 0.08428, Adjusted R-squared: 0.0722
## F-statistic: 6.972 on 4 and 303 DF, p-value: 2.216e-05
#c
#smallest price = IF
2694.8
## [1] 2694.8
#highest price = VS2
2694.8 + 3163.4
## [1] 5858.2
#d
#The avg price for all other clarity levels (VS1,VS2,VVS1,VVS2)
#is sig. higher than for IF diamonds
- Confounding variable
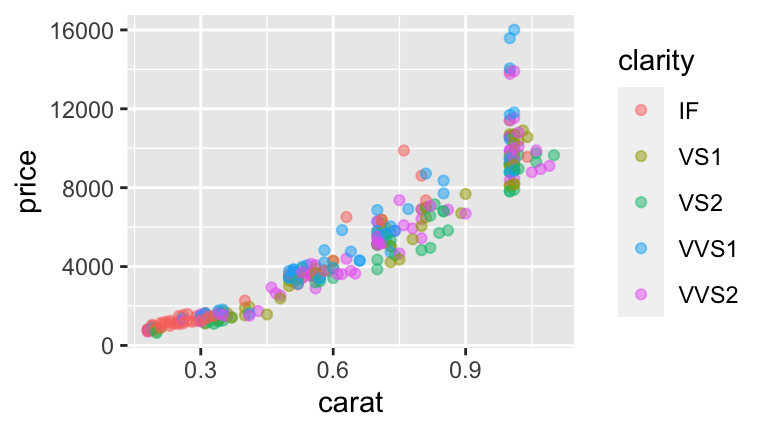
#b
mod2 <- lm(price ~ clarity + carat, diam)
summary(mod2)
##
## Call:
## lm(formula = price ~ clarity + carat, data = diam)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1962.4 -584.1 -62.5 434.8 5914.3
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1851.2 177.5 -10.429 < 2e-16 ***
## clarityVS1 -1001.2 203.0 -4.932 1.35e-06 ***
## clarityVS2 -1561.9 228.2 -6.844 4.30e-11 ***
## clarityVVS1 -403.7 219.7 -1.837 0.0672 .
## clarityVVS2 -958.8 205.8 -4.659 4.78e-06 ***
## carat 12226.4 232.2 52.664 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1029 on 302 degrees of freedom
## Multiple R-squared: 0.9101, Adjusted R-squared: 0.9086
## F-statistic: 611.3 on 5 and 302 DF, p-value: < 2.2e-16
#c
#practice
#d
#highest = IF (all other clarity coefs are negative)
#lowest = VS2 - on average it gets $1561.9 less than an IF diamond
#of the same size
#e
#IF diamonds tend to be small (the bigger the diamond the more room for flaws)
#and small diamonds get less money
ggplot(diam, aes(x=carat, fill=clarity)) +
geom_density(alpha=0.5)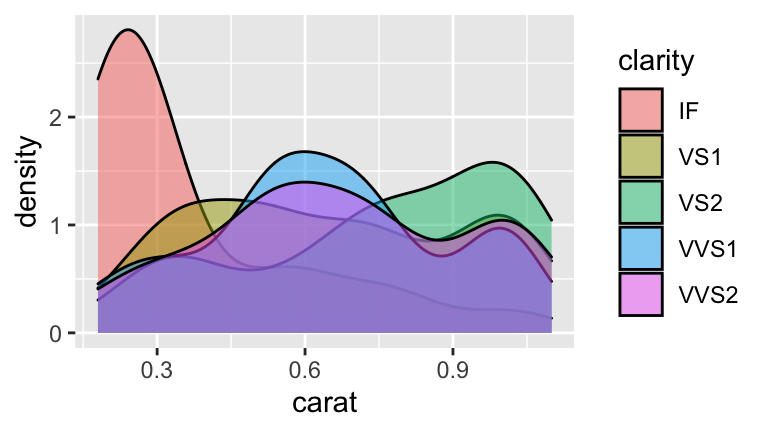
- Diet and birth sex
#a
# Set the seed
set.seed(2018)
# Randomly generate the number of male & female babies for each food
births <- data.frame(nmales = rbinom(n = 132, size = 50, prob = 0.5)) %>%
mutate(nfemales = 50 - nmales) %>%
mutate(food = foods$Type)
#b
births %>% arrange(nmales) %>% head(3)
## nmales nfemales
## 1 15 35
## 2 17 33
## 3 19 31
## food
## 1 Asparagus, fresh/frozen, boiled
## 2 Sour cream dip, any flavor
## 3 Peanut butter, creamy
births %>% arrange(desc(nmales)) %>% head(3)
## nmales nfemales
## 1 35 15
## 2 34 16
## 3 32 18
## food
## 1 BF, dutch apple/apple cobbler
## 2 Applesauce, bottled
## 3 BF, applesauce
#c
#Conclude that a food is linked to birth sex when it's not.
#d
get_p <- births %>%
group_by(1:n()) %>%
do(prop.test(x = .$nmales, n = 50) %>% tidy())
births <- births %>%
mutate(p.value = get_p$p.value)
#e
births %>% filter(p.value < 0.05)
## nmales nfemales
## 1 15 35
## 2 17 33
## 3 34 16
## 4 35 15
## food p.value
## 1 Asparagus, fresh/frozen, boiled 0.007209571
## 2 Sour cream dip, any flavor 0.033894854
## 3 Applesauce, bottled 0.016209541
## 4 BF, dutch apple/apple cobbler 0.007209571
mean(births$p.value < 0.05)
## [1] 0.03030303
- Breakfast cereal and birth sex
0.05
\(1 - 0.95^2 = 0.0975\)
\(1 - 0.95^{100} = 0.9940795\)
0 are still significant:
births %>% filter(p.value*132 < 0.05)
## [1] nmales nfemales food p.value
## <0 rows> (or 0-length row.names)- By making it harder to make Type I errors, we increase the probability of making Type II errors (missing real results).
- Let’s clean up this data
Rides <- read.csv("https://www.macalester.edu/~ajohns24/Data/NiceRide2016sub.csv")
Rides <- Rides %>%
rename(duration=Total.duration..seconds.) %>%
dplyr::select(c(Start.date, Start.station, End.station, duration, Account.type)) %>%
filter(duration > 0) %>%
mutate(hours=as.factor(hour(mdy_hm(Start.date))), months=as.factor(month(mdy_hm(Start.date))))
- Duration vs Membership Status
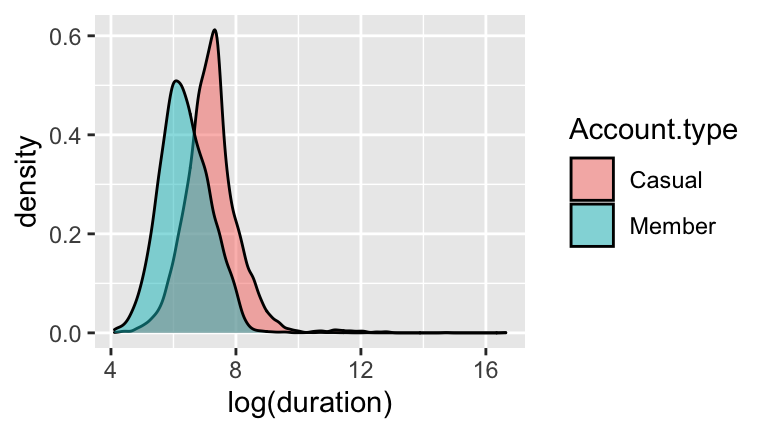
#b
summary(lm(log(duration) ~ Account.type, Rides))
##
## Call:
## lm(formula = log(duration) ~ Account.type, data = Rides)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.0957 -0.5390 -0.0505 0.4954 9.4142
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.22288 0.01108 651.93 <2e-16 ***
## Account.typeMember -0.84616 0.01373 -61.64 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8373 on 16376 degrees of freedom
## Multiple R-squared: 0.1883, Adjusted R-squared: 0.1883
## F-statistic: 3799 on 1 and 16376 DF, p-value: < 2.2e-16
#interpretation:
#the typical duration of a member's ride is 13 min
#shorter than the typ. duration of a non-member's ride
(exp(7.22288) - exp(7.22288-0.84616))/60
## [1] 13.04057
#c
#yes. the p-value for the Account.typeMember coef is < 0.05
- Duration vs Month
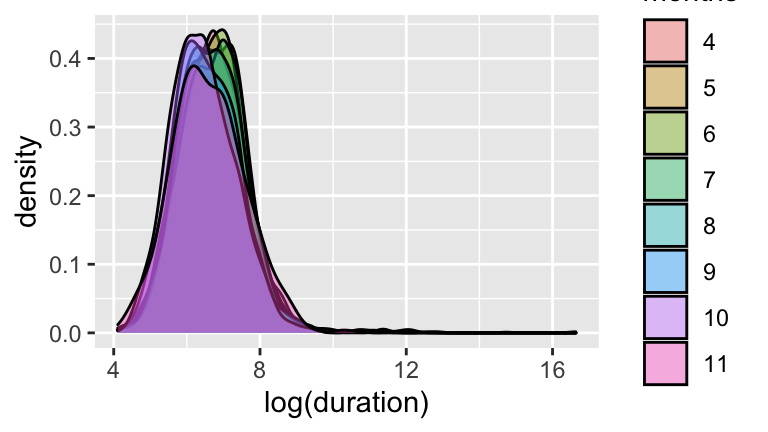
#b
summary(lm(log(duration) ~ months, Rides))
##
## Call:
## lm(formula = log(duration) ~ months, data = Rides)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.6494 -0.6422 -0.0228 0.5857 9.9506
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.686459 0.025855 258.614 < 2e-16 ***
## months5 0.073814 0.032084 2.301 0.021423 *
## months6 0.026429 0.031286 0.845 0.398272
## months7 0.047594 0.030611 1.555 0.120016
## months8 0.006052 0.031488 0.192 0.847579
## months9 -0.119706 0.032645 -3.667 0.000246 ***
## months10 -0.227514 0.034588 -6.578 4.92e-11 ***
## months11 -0.081611 0.055184 -1.479 0.139191
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.925 on 16370 degrees of freedom
## Multiple R-squared: 0.009602, Adjusted R-squared: 0.009178
## F-statistic: 22.67 on 7 and 16370 DF, p-value: < 2.2e-16
#interpretation:
#the typical duration of a ride in May is 1 min
#longer than the typ. duration of a ride in April
(exp(6.686459) - exp(6.686459+0.073814))/60
## [1] -1.023309
#c
#yes, the p-value for `months5` < 0.05
#d
#sample size. when n is large, standard error is small,
#thus even small, unmeaningful effect sizes are statistically significant
- Play Around!
#a
Stations <- read.csv("https://www.macalester.edu/~ajohns24/Data/NiceRideStations.csv")
#join the Stations and Rides
MergedRides <- Rides %>%
left_join(Stations, by=c(Start.station = "Station")) %>%
rename(start_lat=Latitude, start_long=Longitude) %>%
left_join(Stations, by=c(End.station = "Station")) %>%
rename(end_lat=Latitude, end_long=Longitude)
#b
MN<-get_stamenmap(c(-93.375,44.86,-93.05,45.04),zoom=14,maptype="terrain")
#MN <- get_map("Minneapolis", zoom=13)ggmap(MN) +
geom_segment(data=MergedRides, aes(x=start_long, y=start_lat,
xend=end_long, yend=end_lat), alpha=0.07)
#c
ggmap(MN) +
geom_segment(data=MergedRides, aes(x=start_long, y=start_lat,
xend=end_long, yend=end_lat), alpha=0.1) +
facet_wrap(~Account.type)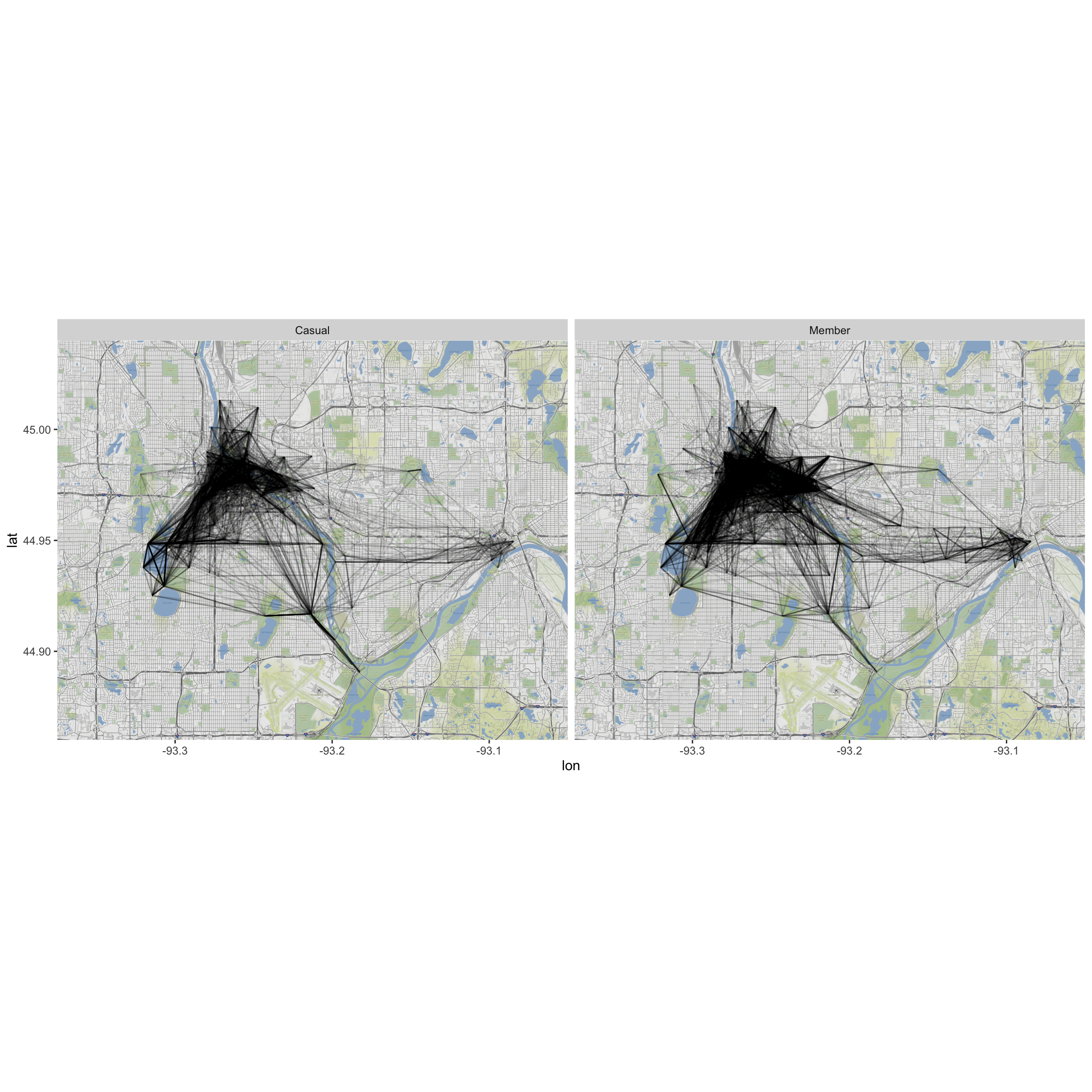
#d (incomplete answer)
ggmap(MN) +
geom_segment(data=MergedRides, aes(x=start_long, y=start_lat,
xend=end_long, yend=end_lat), alpha=0.12) +
facet_wrap(~hours)