Unit Overview
Motivation
In Unit 2, we learned to use univariate probability models to answer questions such as:
- What height (\(Y\)) might we expect A person to have?
In Unit 3, we learned to use joint probability models to answer questions such as:
- What combined height (\(Y\)) and wrist circumference (\(X\)) might we expect A person to have?
and conditional probability models to answer questions such as:
- If A person has wrist circumference \(X\), what height (\(Y\)) might we expect them to have?
Yet in working with data, we tend to have more than A subject or person, we might have a sample of size \(n > 1\). In Unit 4, we’ll explore properties of random samples. For example, in a sample of \(n\) adults:
What would we expect the average height to be? The maximum height? How might this vary from sample to sample?
What would we expect the relationship between height and wrist to be in the sample? How might this vary from sample to sample?
DEFINITION: random samples
Let \((X_1,X_2,...,X_n)\) denote a set of measurements (data) taken on a sample of \(n\) “objects”. For example, the \(X_i\) might be the heights of \(n\) individuals sampled from the population of all adults. We say that the \(X_i\) are independent & identically distributed (iid) (or the \(X_i\) are a random sample) if they satisfy 2 conditions:
\(X_i\) are independent; and
all \(X_i\) are drawn from the same “population”/model with common PDF \(f_X(x)\), CDF \(F_X(x)\), and MGF \(M_X(x)\).
UNIT 4 GOAL
In Unit 4 we’ll study the features of random samples taken from a given, specified model:
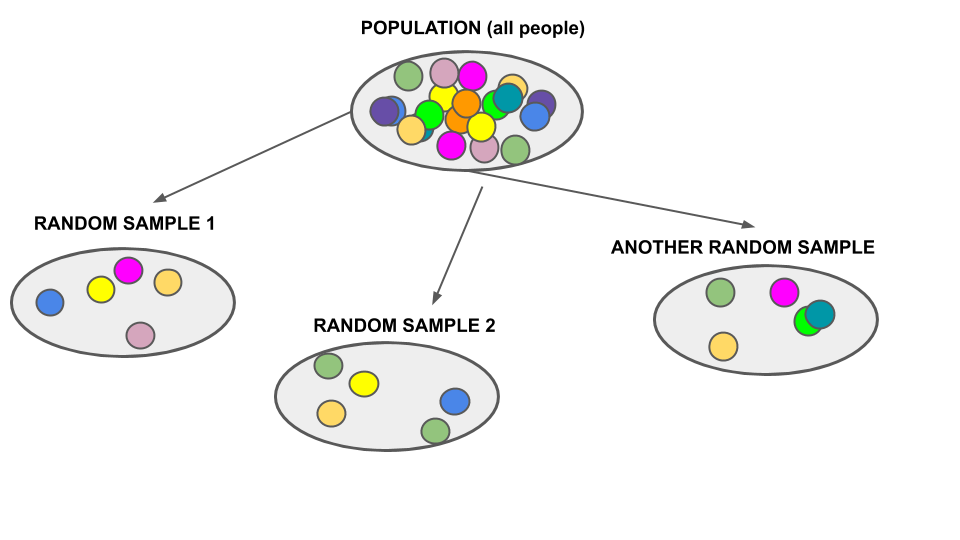
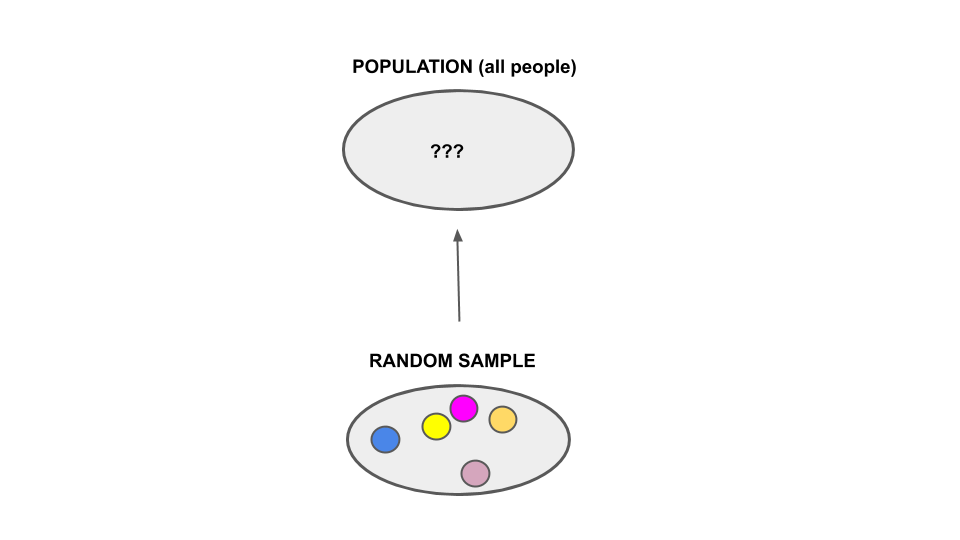
This understanding provides the theoretical framework for data analyses (like those in the motivating examples above) which reverse the question. Instead of asking how random samples from a known model might behave, they ask what an observed random sample can tell us about the unknown model from which it was generated. In other words, data analyses use observed data from a random sample to make inferences, or learn, about the broader and unobserved population of interest:
NOTE:
- MATH/STAT 354 covers the theory required to answer the first question: if we know the probability model, how would we expect random samples from this model to behave?
- MATH/STAT 455 covers the theory required to answer the second question: if we have a random sample of data, what does this tell us about the underlying, unknown model?
STAT 155, 253, 451, 452, 453, 454 apply this theory to make inferences from data:
- What conclusions can we make about the effectiveness of a COVID-19 vaccine based on its performance amongst a sample of \(n\) people?
- What conclusions can we make about the severity of COVID-19 symptoms amongst different age groups based on a sample of \(n\) patients?
- What conclusions can we make about the effectiveness of a COVID-19 vaccine based on its performance amongst a sample of \(n\) people?